科学家开发出准确捕捉表情的3D建模新方法
在3D渲染中准确地重建一个人的面部特征,是3D扫描仪所要面对的最困难的工作之一。虽然各种技术和软件已经发展了很多年,但人脸的高度非刚性性质,以及人类本身能够分辨出非常细微的细节和几何缺陷的能力,使得生成一个高频品质的渲染效果非常困难。此外,它还是一个非常耗时的过程,并且需要大量的设备。受测者将被长时间锁定在一个工作室里,同时要设置几十个摄像头来收集必要的数据。
但是,在今年9月6日—12日在瑞士苏黎世举行的计算机视觉欧洲会议(European Conference on Computer Vision)上,来自华盛顿大学的团队展示了一种3D扫描获取面部特征的新方式,可以避免这一切,而且使用的设备非常简单,不需要特殊的装置。
“前提是,我们能够获取一个人在不同时间、不同环境,以不同的表情和姿势拍摄的大量照片。事实上,大多数人在生活中总是会拍摄大量的照片和视频。我们的建议是利用同一个人的所有可用图片和视频作为资料库,来帮助在虚拟世界重建他/她的脸部。”

他们的做法被称为总体移动脸部扫描(Total Moving Face Scanning,TMFS),研究团队成员包括华盛顿大学计算机科学与工程研究生 Supasorn Suwajakorn和他的导师助理教授 Ira Kemelmacher-Shlizerman、教授 Steven Seitz。

这种TMFS方法,可用于在非正常拍摄条件下的3D建模。特别是那些有着大量公开图像、视频数据的知名人士,诸如查尔斯王子、阿诺德·施瓦辛格、汤姆·汉克斯这类人。这应该也算大数据的一种使用方式吧。
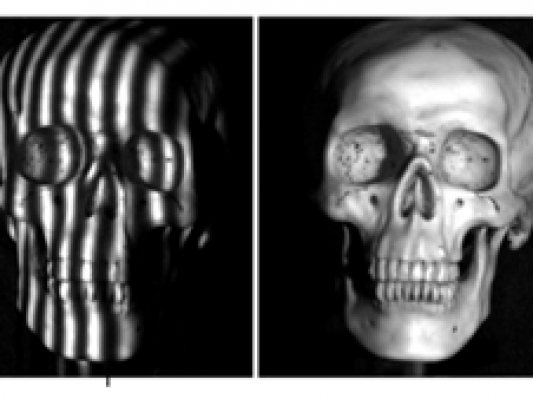
从下面的图片中可以看到,软件在综合了各种光照条件、头部姿势、面部表情等数据生成了高度详细而精确的3D渲染效果。

这种方法显然与常用的技术大不相同。“当前几乎所有的3D人脸追踪和视频重建方法都是基于一个假设,即人脸可以通过混合形状的线性组合来表现。”虽然这种方法可以科学家限制参数和测量指标的数量,但它会导致在低等级的3D模型中,表现力有限,而且无法捕捉一些重要细节。
使用TMFS方法,目标对象的图像视频数据越多,那么计算生成的3D形象就会越精确传神。一个人的脸部形状可以在每个时刻都稍有不同,但是它们的大致形状(例如眼睛、鼻子的长度,整体几何形状之间的距离等),趋向于随着时间的推移保持一致。因此,研究人员可以利用所有可用的图像(照片和/或视频帧)来捕捉特定条件下的平均形状和外观,来重建一个人的外观和形状的3D模型。
3D渲染本身就是一种复杂的算法。 至关重要的是一个“照片一致性基础上的标准,比如在同一个输入视频帧中比较网格效果。这种能力的关键取决于每个输入帧的渲染网格能否匹配。”

TMFS方法的渲染过程包括了两个步骤:第一、平均形状(基于图像数据库)发生变形以匹配3D渲染里同一个形状的运动。第二,所得到的形状要根据每一帧中的已知细部线索进行修改。这意味着,非刚性的面部特征(如皱纹)也将首次捕获并添加到参考帧里,在这之后一些特定的细部也将要考虑在内。 所有这一切,很明显需要一些严肃的计算。

但是结果是不会说谎的。TMFS算法能够成功地清晰捕获类似皱纹这样非常微小的细节和在很小尺度上的微妙表情变化,这是现有软件无法比拟的。 正如科学家们说: “通过注意在每帧中面部表情的变化(相对于平均形状),例如,嘴张开、眼睛闭合和打开、皱纹出现和消失、眼睛区域的细节等,诸如此类。该方法即使在对象动作幅度非常大的条件下也很可靠,即使是简单的轮廓也能提供高品质的结果。”
TMFS技术的应用前景十分广阔,它可以用来开发基于视频和照片的3D建模软件,让对人像的3D扫描和建模变得更加简单、方便、精确。同时也否定了使用昂贵的设备来获得高质量结果的必要性。
来源:天工社